
貨物盗難は転換点を迎えています。米国およびカナダの貨物ネットワーク全体での損失は現在、年間350億ドルを超え(CargoNet 2024)、発生件数は前年比57%増、平均損失額も恒常的に58万ドルを上回っています。最も大きく変わったのは脅威の性質です。物理的なハイジャックは減少し、代わりに、デジタル詐欺、キャリアのなりすまし、輸送途中積み替えでの不正な貨物引き渡しなど、キャリア審査の隙を突く手口へと移行しています。
市場もこの状況に対応し、2025年にはリスク対策ソフトウェアへの支出が前年比約18%増となっていますが、依然として盲点は存在します。偽の身元情報、輸送途中の引き継ぎ、規制違反ルートの利用などは、十分に審査されたネットワークであってもすり抜け続けています。project44は、位置情報とコンプライアンスのシグナルをリアルタイムのリスク・インテリジェンス層として構築・統合することで、こうしたリスクの穴を埋めるうえで独自の強みを持っています。これにより荷主は、脅威が発生した瞬間に検知・防止・対応できるようにします。
進行中の脅威を示す最も早く信頼性の高いシグナルは、「想定どおりに動かなくなったトラック」です。計画されたルートから外れる、異常に長く停滞する、前進せずに行ったり来たりする——まさにこのような挙動こそがルート逸脱検知の対象です。
ルート逸脱とは何か、そして詐欺防止において重要な理由
ルート逸脱とは、集荷から配送までの間に、貨物が想定された輸送経路またはスケジュールから外れることを指します。実務上、これらのシグナルは詐欺や盗難のパターン、マイルストーンの未達、そしてETA精度の連鎖的な悪化と強く相関します。逸脱を重要な例外として扱うことで、荷主は損失が顕在化する前に、キャリアへの連絡、警備の手配、ルート変更などの対応を実行できます。
異常はどのように検知するのか?
project44では、追跡している貨物に対して1日あたり300万件以上のGPS データ(ping)を受信しています。世界全体では1日あたり5万件以上の貨物を追跡しており、その大半は想定どおりの集荷・荷下ろしの予約時刻と軌跡に沿って移動します。これらの中から詐欺パターンを見つけ出すのは、干し草の山から針を探すようなものです。規模の大きさに加え、さらに事前に詐欺パターンが分かっているわけでも、正解ラベル付きのデータセットがあるわけでもありません。
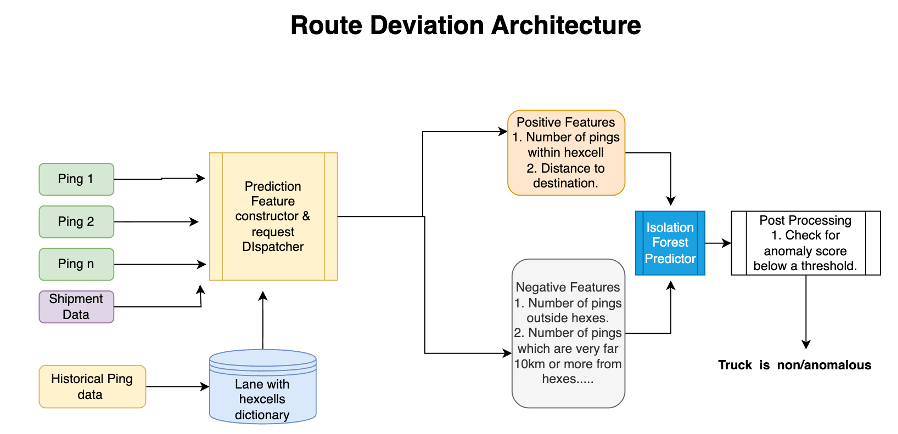
そのため、ラベルがないデータから、洞察を創出し、パターンを発見する「教師なし学習」を採用しました。具体的には、異常スコアに基づいて外れ値を検出するIsolation Forestアルゴリズムを採用しました。このアルゴリズムは線形時間計算量で動作するため、モデルの学習と推論の双方で高速です。
検知エンジンの仕組み
貨物が生成する各GPS データ(ping)は、リアルタイムで次の2つのモデルに対して評価されます。
- 距離逸脱:トラックが想定されるルートからどれだけ外れたかを測定
- 時間逸脱:トラックがルート上にいる間でも、前後移動、出発地点方向への逆行、前進の欠如など、異常な動きを検知します。
各pingデータには異常スコアが付与されます。その後の後処理で、これらのスコアをドメインルール(連続異常回数、レーンからの距離しきい値、速度/逆行チェックなど)と統合し、貨物単位の判定を行って、説明可能な例外を生成します。
通常状態の地図を構築:ヘクスセルによる参照レーン
想定ルートは「ヘクスセル・レーン(hexcell lanes)」として符号化されます。これはルートを小さな地理空間にグリッド分割し、それらを組み合わせて、特定の出発地—目的地ペアにおける通常の経路がどのようなものかを定義します。これらのレーンは過去データから構築され、システムが各ライブpingデータを評価する際の基準となります。お客様は、自社の貨物輸送履歴を用いた自社ネットワークに特化したカスタムベースラインを構築することも可能です。project44ではすでに100万以上のレーンをマッピングしており、これらのモデルを構築・拡張するための強固な基盤を提供しています。
システムが監視する詐欺シグナル
すべての逸脱が同じ形をしているわけではありません。システムは次の3つの異なるパターンを検知します。
- 急速なレーン逸脱:無許可の迂回や予定経路外移動の初期兆候
- レーン上での継続的な異常滞留・往復:予定経路から外れないものの移動が止まる、潜在的な待機や抜き取り
- 経路未完了:目的地到達が時間的・距離的に困難な状態(未配達リスク検知)
エンド・ツー・エンドの処理フロー
各GPS データは逸脱サービスにストリーミング処理され、2つのIsolation Forestモデルが距離ベースおよび時間ベースの異常について独立にスコアリングします。これらのスコアは、ノイズを抑制するために調整済みのしきい値と連続性条件でフィルタリングされ、逸脱が確定すると、位置・時間・、種類、重大度を含む例外がプラットフォームに公開され、即時対応に備えます。
内部構造:モデルの構築とチューニング方法
データセットの構築
北米と欧州にわたる10万件超の貨物と500万件のGPSデータ(ラベルなし)で学習させました。正解データが存在しない中で、まず初期のしきい値スコアを適用し、フラグが立ったケースを目視で確認するとともに、抽出した逸脱をアノテーションチームに回することでブートストラップを行いました。彼らからのフィードバックを基に反復的に改善を重ね、最終的にゴールデンバリデーションセットを構築すると同時に、閾値の精緻化を進めました
特徴量エンジニアリング
各GPSデータが送信されるたびに、システムは複数の観点かrシグナルを評価します。具体的には、トラックが本来の想定ルートからどれだけ外れているか、速度や移動パターンに不自然な点がないか、目的地に向かってきちんと前進しているか、そして移動のタイミングがそのルートで通常想定される範囲内かどうか、などの点を確認します。これらのうち、「位置のずれ(距離)」と「動きや時間の異常」は、それぞれ別のモデルで個別に分析されており、各モデルが特定の要素に集中することで、より正確な判断ができるようになっています。
後処理のセーフガード
このシステムは、本当に注意が必要な場合にだけアラートを出すように設計されています。1回だけ不審なGPSデータが検出された場合ではなく、複数回連続して異常が確認されたときに初めてアラートが発生する仕組みになっており、休憩のための一時停止やちょっとした寄り道といった通常の動きを誤って異常と判断してしまうリスクを抑えています。また、異常とみなす基準(しきい値)は、それぞれの輸送ルートの特性に合わせて調整されています。そのため、「どこからが異常か」という判断は一律ではなく、そのルートごとの通常の動きに基づいて決まるようになっています。
評価
正解データ(あらかじめ「正常」や「異常」とラベル付けされたデータ)が存在しないため、私たちは実際に観測できる結果に基づいて評価を行う独自の仕組みを構築しました。この評価では、2つの重要な判断基準を軸としています。1つ目は、トラックが最終目的地への到着を一度も記録していない場合で、これは明確な異常(ルート逸脱)とみなされます。2つ目は、アラートが発生した後にトラックが大幅に遅れて到着した場合で、このケースではモデルが実際の遅延やルート逸脱を正しく検知できていたと判断されます。
しかし、実際に検知された多くのケースは、これら2つの基準のどちらにもきれいに当てはまるものではありませんでした。こうしたケースを検証するために、私たちはFoliumを用いた地図可視化を構築しました。そこでは、基準となるルート、リアルタイムのGPSデータ、そしてモデルの判定結果を重ねて表示し、それぞれのケースを視覚的に確認できるようにしています。これにより、個々の判断を目で見て検証し、システムの判定に対する信頼性を高めています。
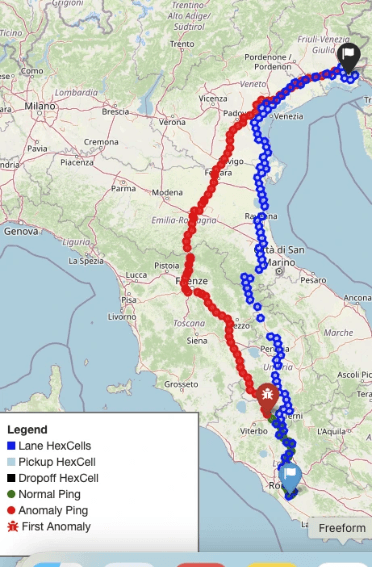
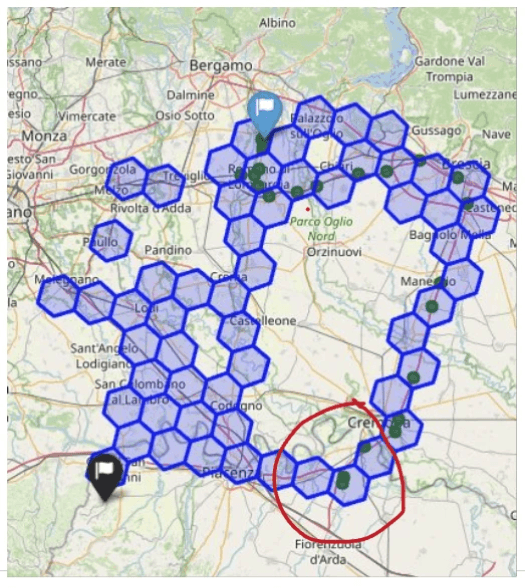
このルート逸脱検知システムは現在、本番環境で稼働しており、拡張性の高いFastAPIおよびGKE(Google Kubernetes Engine)を用いた基盤上で、毎日数百万件のGPSデータを処理しています。そして、異常の可能性を示すリアルタイムのアラートや、リスクの高いルートに関するインサイトを、お客様に直接提供しています。
検知からアクションへ
今後は、ルート逸脱検知をAIによるエージェント型ワークフローと統合していきます。これにより、エージェントがこの情報をもとにキャリアや顧客へ連絡を行い、次に取るべき対応を判断できるようになります。例外は貨物単位でプラットフォーム上に例外として表示され、逸脱が発生した位置や時刻もUI上で強調表示されるため、今後の再発防止に役立てることができます。不正行為は、多くの場合、マイルストーンに問題が現れる前にルートの操作として発生します。本システムでは、リアルタイムの位置情報を信頼できるルートや通常の進行パターンと継続的に照らし合わせて評価することで、逸脱が発生した初期段階で検知し、即座のエスカレーションを可能にしています。その結果、損失の削減、インシデント発生時の迅速な回復、そして配送の信頼性向上といった効果が実現されます。
結論と次のステップ
本取り組みにより、project44において初となる不正検知システムを実装し、現在は複数の顧客に向けてこの機能の展開を進めています。キャリアはこの情報をもとにトラック運転手へ連絡し、必要な対応を取ることが可能になります。今後は、リアルタイムのニュースデータを取り込み、リスクの高いエリアを特定することで、事前に対策を講じられるようにすることも検討しています。詐欺や不正事象が増加していく中で、現在のように人手で逸脱を評価する方法では対応しきれなくなるため、自動化された処理基盤の構築が求められます。現時点では、可視化結果を人が目で確認しており、この検証プロセスには多くの時間がかかっています。そこで現在、逸脱の自動ラベル付けや説明生成を行う、エージェント型のLLM(大規模言語モデル)を活用したアプローチの開発を進めています。この取り組みについては、今後、技術的な詳細解説を別途公開する予定です。


