
ロジスティクスにおいて、ETA(到着予定時刻)の精度は単なる指標ではありません。サプライチェーンにおいて、それは、後工程のオペレーション全体を支える基盤です。ETAが守られないと、ドックの遅延、作業員の待機、生産の混乱、そして顧客満足度の低下へと連鎖的に影響します。しかし、トラック輸送の到着時間を予測することは本質的に複雑です。出荷に対する業務内容、キャリアネットワークの要因、GPSテレメトリ、そして人間の行動など、あらゆる要素が結果に影響を与えます。
そのため、顧客から「ETAの精度が低下している」と指摘された場合、即座に浮かぶ疑問は「なぜか?」です。
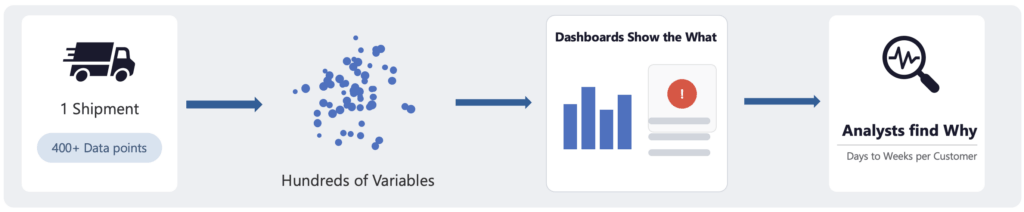
現在、その問いに答えるには、分析担当者が最大2週間をかけて400以上の業務変数を精査し、毎回ゼロから分析を構築する必要があります。ここで課題となるのは、分析担当者はパターンの意味を理解していますが、その大半の時間をパターンを見つけ出すことに費やしているということです。分析されたパターンに基づいて実際に行動を起こしているわけではないのです。
project44はその比率を逆転させるシステムを構築しました。弊社のエージェント型アナリティクスのワークフローが探索と根本原因の特定を処理するため、分析担当者は洞察をアクションに変換することに集中できるようにします。
コンテキスト化:データ分断という障壁を乗り越え、業務文脈を理解するエージェントを構築
project44は何百万ものFTL出荷を追跡しており、1つの出荷から、出荷属性やGPSテレメトリ、待機時間、予測フィードバックなど、400以上のデータポイントが生成されます。精度低下の根本原因は、GPS信号の発信品質低下、ルートの複雑性、予約時間の遵守率、その他の複数の要因が交差する地点に潜んでおり、何百もの無関係な変数の中に埋もれている可能性があります。
ダッシュボードは「何が起きているか」(パフォーマンスの低いキャリアや問題のあるルートなど)を表面化させます。しかし、「なぜか」を特定するには、顧客ごとに数日から数週間を要し、異なる業務特性の違いをまたいで再利用可能な分析手法は存在しません。
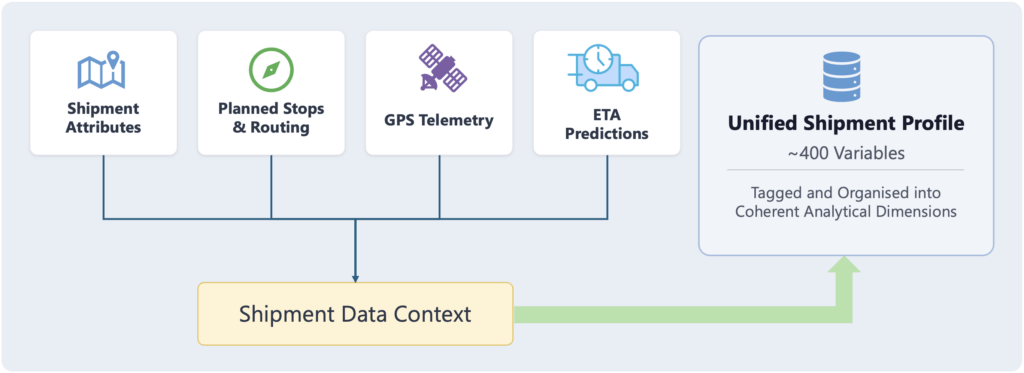
分断された指標から統合された出荷プロファイルへ
システムがETA精度を分析するためには、最初に、分析担当者が手動で収集するのと同等のコンテキスト(出荷属性、立ち寄り順序、GPSテレメトリデータ、施設での滞在時間、ETA予測履歴)が必要でした。これらを各出荷ごとに約400の変数に統合・整理し、分析可能な次元に構造化
しました。これがエージェント型ワークフローが動作する基盤となります。
自律型アナリティクスへの進化
構築したこの統合データレイヤーを基に、project44のアーキテクチャは3つの段階を経て進化しました。
ステージ1:LLMツール利用ループ
最初のアプローチでは、AIに分析ツールへの直接アクセス権を与え、自由に探索させました。その結果、戦略的な方向性がなく、再現性も欠け、コスト予測もできず、実行前の人間による監視もありませんでした。ただ一つ維持されたのは、すべての結論がデータから計算された指標に裏付けられており、決して捏造されなかったことです。戦略は不十分でも、分析の基盤自体は健全でした。
ステージ2:計画 -> 実行

即座に行動する代わりに、システムはまず、人間が読める構造化された分析計画を生成し、分析担当者が(計算が実行される前に)計画を確認・編集・承認します。これにより、再現性、コスト予測可能性、そして信頼性がもたらされました。ただし、計画は依然として静的であり、実際の結末を見る前に、システムはすべての深掘りステップを事前に想定する必要がありました。
ステージ3:多層階の仮説駆動型分析
突破口は、上級分析担当者の思考プロセスを模倣することから生まれました。何を深掘りすべきかを知るまでは、深掘りの計画は立てられません。現在、システムは2つのレベルで動作しています。
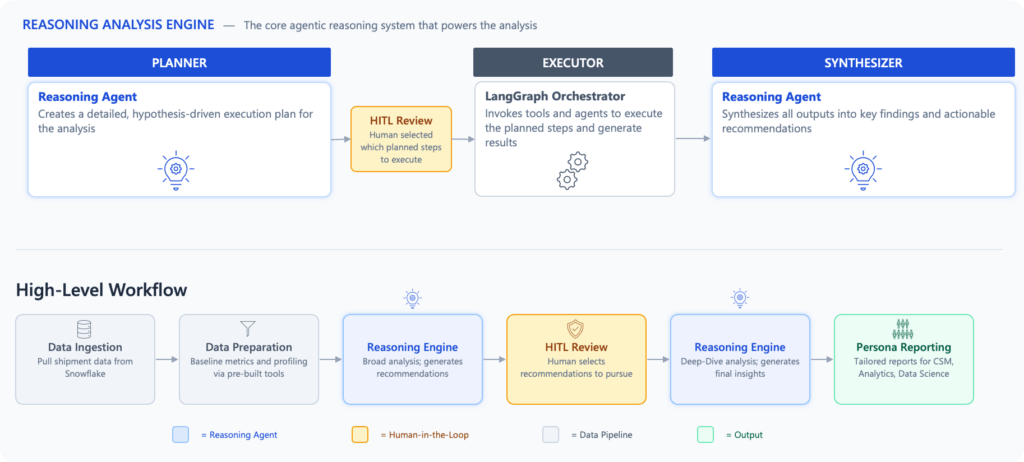
レベル1 – 全範囲の探索:システムはフィルターや前提なしにデータセット全体をスキャンします。各分析ステップには、ある要因がETA精度に「影響する」と「影響しない」という対になる仮説を設定します。これにより、システムは直感を裏付けるのではなく、発見の証明を要求します。結果として、エビデンスに基づいた優先順位付きの問題領域が抽出されます。
レベル2 – エビデンスに基づく深掘り:レベル1で特定された上位の発見事項のみが次に進みます。データフィルタリングが許可されるのはこの段階のみであり、システムの早期の視野狭窄を防ぎます。
例えば、レベル1で、特定キャリアが顧客にとって大きな輸送量を占めている一方で、ETA精度が低いことを特定したとします。同時に、GPSカバレッジが非常に低い(0〜25%)出荷も精度が低いことが判明したとします。
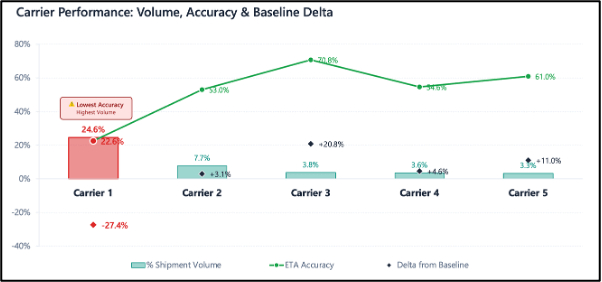
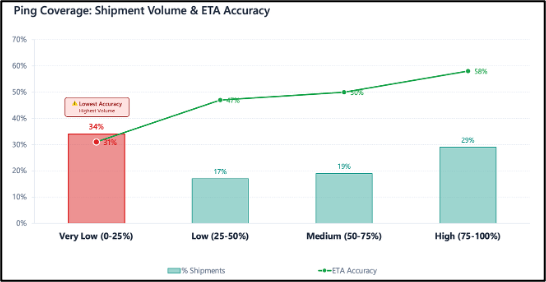
レベル2では、その該当キャリアについて深掘りすると同時に、そのキャリアに特化したGPSカバレッジを詳細に分析します。
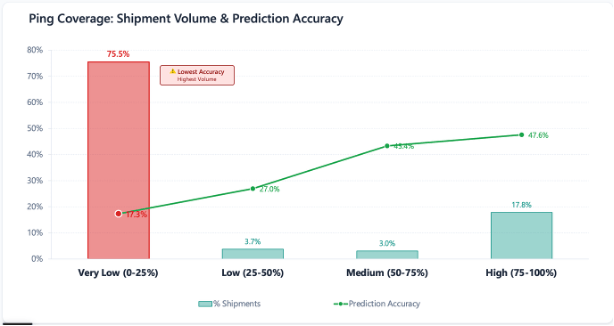

両方のレベルにおいて、分析者は計画のレビュー、発見事項の検証、そしてどの推奨事項を実行に移すべきかの判断に関与し続けます。
人間の役割:意思決定インテリジェンスの高度化
この自律型フレームワークの目標は、分析担当者の自動化による置き換えではなく、発見フェーズを自動化することです。以前は数週間かかっていた徹底的なデータのクリーニングや関係性の探索を自動処理することで、人間の関与(HITL:ヒューマン・イン・ザ・ループ)はより高度で戦略的なレベルに引き上げられます。
これこそが意思決定インテリジェンスの本質です。もはや「何が起きたか」を問うことに時間を費やす必要はありません。代わりに、AIが提示したエビデンスを基に、問題の緩和・連携・長期戦略に集中できます。エージェント型ワークフローの圧倒的な処理能力と上級分析者の高度な知見を組み合わせることで、断片的なデータをグローバルサプライチェーンのための明確で実行可能なロードマップへと変えています。
成果
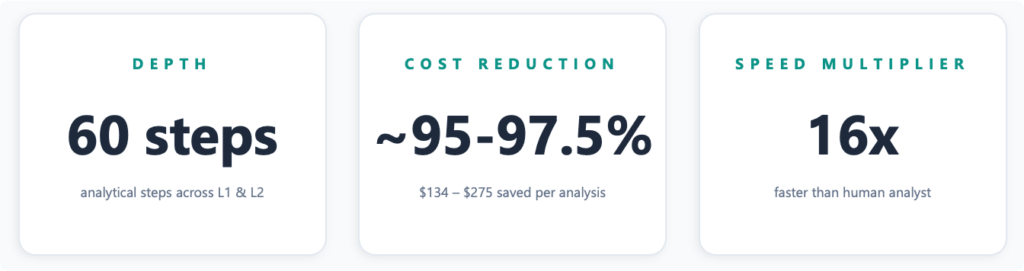
洞察の深さ: 標準的な実行では、L1とL2の両方で60の分析ステップが実行され、セグメント分析、トレンド分析、異常検知、エンティティ単位の深掘りを行います。検証では、従来の手作業での分析では特定できなかった新しい要因をシステムが特定しつつ、既存の要因をすべて網羅します(見落としゼロ)。
スピード: 洞察を得るまでの時間が約1時間に短縮され、手動による深掘り分析と比較して平均16倍の短縮を実現しました。
コスト: エージェント型ワークフローの実行により、95%の大幅なコスト削減が実現されました。
検証方法
同じデータセットと顧客に対して、過去の手動分析の結果と、システムの出力を比較しました。
ワークフローは、元の分析からのすべての要因を特定しました。手動分析と100%重複しただけでなく、分析担当者が見つけられなかった新しい要因も発見しました。ほとんどの分析アプローチが一致し、ワークフローはさらに1つの追加アプローチを導入しました。唯一の差分はレポート粒度でした。セグメントレベルの内訳は計算されていましたが、自動レポートには完全には反映されていませんでした。しかしこれはテンプレートの問題であり、分析の問題ではありません。

再現性をテストでは、2つの異なるデータセットに対して全く同じ入力でワークフローを3回実行しました。主要な結果と推奨事項は80〜85%の重複があり、安定していました。異なるデータセット間では、システムはそれぞれ固有のインサイトを生成し、固定ロジックではなくデータに基づいて推論していることを確認しました。
学んだこと

今後の展望
現在、システムは根本原因の特定まで実現しています。次のステップは、それらに基づいて自動的に行動することです。
検知から修正へ: 分析結果を後工程のエージェント型ワークフローに直接連携し、手動の介入なしにETAモデルやパイプラインを改善するための実験を自動実行させます。
人間主導から自己学習へ: 分析担当者のあらゆる判断、顧客対応、過去の実行結果を学習し、強化信号としてフィードバックします。 システムはどの分析パスが成果を上げるかを学習し、信頼が高まるにつれてHITL(人間の関与)を段階的に減らしていきます。
リアクティブ(事後対応型)からプロアクティブ(予測・実行型)へ。 重要顧客向けの分析を自動生成し、問題が深刻化する前に各部門に合わせた洞察を提供します。また、ステークホルダーが必要に応じてオンデマンドで分析を実行できるセルフサービスUIレイヤーも開発・提供します。


