ETAがひとつでも遅れると、ドックでの遅延、作業員の待機、生産スケジュールの乱れ、顧客の失望などの連鎖反応が引き起こされます。 正確な到着時間は、サプライチェーンの効率化において極めて重要です。なぜなら、正確なETAにより、ロジスティクスネットワーク全体で計画、調整、リソースの配分を最適化できるようになるからです。
信頼性の高いETA情報があれば、企業は遅延を予測したり、待機時間の低減、倉庫やドック業務の最適化、顧客への納期維持が可能になります。 その結果、顧客満足度の向上、業務コストの削減、生産停止や在庫切れなどの混乱の防止につながります。 ただし、トラック積載貨物の到着予定時刻を予測するには、天候、交通量、季節性、レーン変動、業務の特性、さらには人間の行動など、ETAに影響を与える様々な特徴を捉える堅牢な機械学習モデルが必要であることです。
トラック積載ETAの問題を解く
小包配送とは異なり、トラック輸送は「道路上の移動時間」だけでは測れません。 貨物スケジュールには、以下のものが含まれます。
- 各停車地間の走行時間。
- 施設内の滞留時間(倉庫やヤードなどでの、積み込み、荷降ろし、書類作業を待っている時間)。
- 燃料補給、食事、または軽い休息のための短い休憩。
- 夜間や長時間休息のための長い休憩。
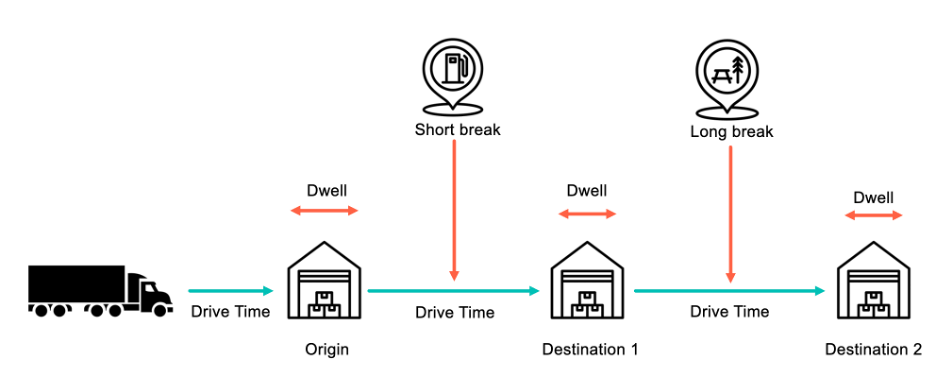
短距離輸送では、1つの施設で遅延するだけでスケジュール全体に影響を与える可能性があります。 長距離輸送では、休息義務や予期せぬ対流がさらに大きな要因となることがあります。 そして、これらは制御可能な要素に過ぎず、交通渋滞、気象事象、ヤードの混雑などにより、不確実性がさらに増します。
問題を悪化させているのは、データ品質のギャップ(GPS信号の途切れやマイルストーン更新の欠落)、数千ものルートにおける車線レベルの変動性、キャリアや施設間の運用上の違いです。 単純な距離ベースのモデルでは、この複雑さを捉えることはできません。
FTL(フルトラックロード) ETAの測定方法
ETAの精度を測定するために、「実際の残り時間(Actual Hours Out)」と「予測される残り時間(predicted Hours Out)」という2つの補完的な指標を追跡します。
これら2つの指標を組み合わせることで、ETAがどれだけ正確であったかだけでなく、どれだけ事前に通知できたかという「精度」と「実用性」の両面を評価します。

正確なETA予測が難しい理由
ETAの精度を高めるには、以下のような課題を体系的に解決する必要があります。
- データ品質の問題:ping(信号)が常に来なかったり、低品質な位置信号、マイルストーン未更新はによる信頼性の低下。
- レーン&貨物の多様性:輸送ルートや距離、インターモーダル(トラック-鉄道-トラックなどの複数輸送モード)が多岐にわたり、 各レーンの動作は異なるため、多様なネットワークで常に良いパフォーマンスを発揮する単一モデルを構築することは困難です。
- 予定外の滞留:ドライバーの休憩、施設の遅延、ヤード混雑などにより、予測不可能な形で輸送が大幅遅延。
- 外部の要因:気象事象や交通渋滞は非常に変化しやすく、予測が困難。
- 業務の微妙な違い:キャリアの行動やドライバーの習慣の違い、施設の営業時間に関する可視化の不十分さなどにより、結果に差が生じる。
- 体系的な誤差要因:滞留の多いエリア、マイルストーン未達、ルート逸脱、データ不整合により、継続的にETAに誤差が発生する傾向がある。
これらの課題により、実運用環境でのETAの精度維持には、堅牢なデータパイプライン、適応性のあるモデル、継続的なエラー分析と監視が不可欠となっています。
生データから信頼性の高いETAへ:エンド・ツー・エンドの視点
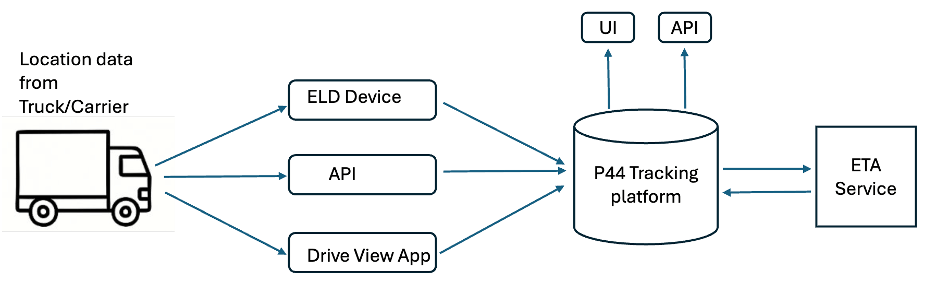
ETAの予測がどのように作成されるかを理解するには、まず輸送プロセスを把握する必要があります。 まず、トラックが出発地から目的地に移動します。次に、位置の更新やマイルストーンの完了などのイベントが発生するにつれて、その情報がproject44の追跡システムに送信されます。 これらのデータは、主に3つの方法で取得されます。
- トラックに搭載されたELDデバイスから発信される継続的なピン信号(位置情報)。
- キャリアと直接EDI / API接続して取得するデータ。
- Drive Viewモバイルアプリから取得する、ドライバーのスマートフォンからの位置データ。
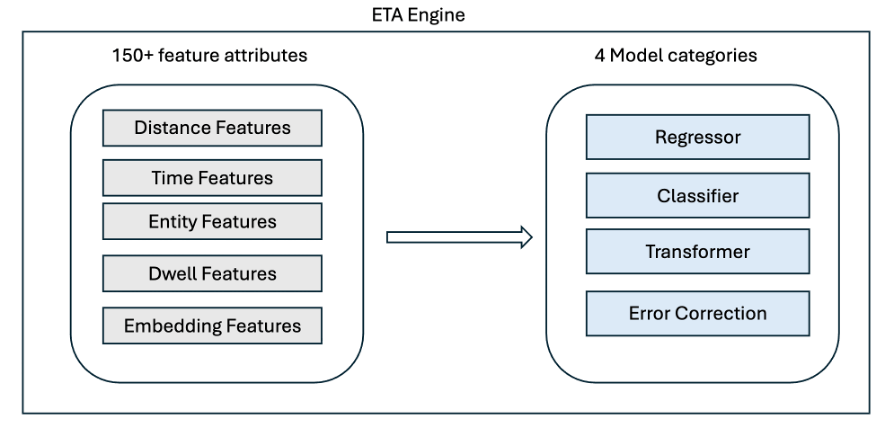
これらの信号はすべてproject44の追跡プラットフォームに取り込まれた後、ETAサービスに送られます。そこで、データサイエンスモデルが予測を生成します。 新しい更新を受信するたびに、ETAサービスは、150を超える入力機能を活用した回帰子、分類子、変換子、エラー訂正フレームワークなど、複数の独自モデルを使用して予測を再計算します。
予測されたETAは、project44のプラットフォームに送り返され、追跡UIに表示され、webhook経由でもリアルタイムの可視化を提供します。
project44独自のETAアプローチ方法
過去1年間で、500社以上の陸上輸送を行う荷主の大規模追跡環境でさまざまなモデルを試し、導入してきました。 合計10以上の本番対応モデルを展開してきました。いずれのモデルも、トラック積載輸送でのさまざまな変動要素を捉えるよう設計されています。 その結果、現実の複雑な環境に適応し、ETA予測で一貫して高い精度を提供する階層化されたETAエンジンを構築しています。
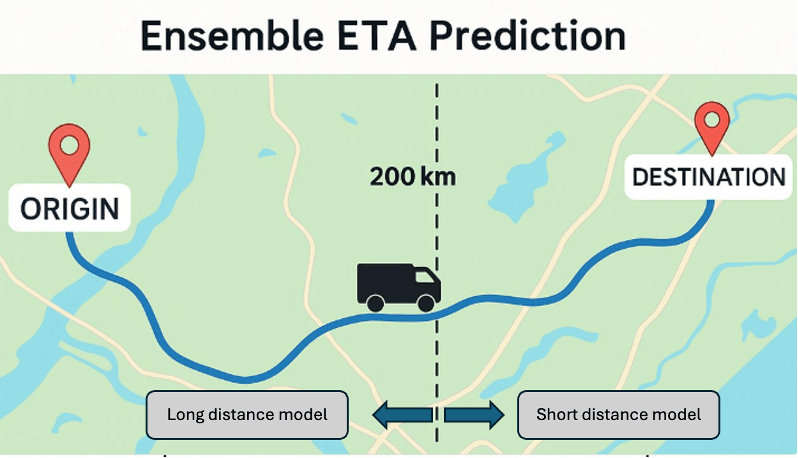
1. アンサンブルモデル
短距離と長距離の輸送では、運行特性が大きく異なります。 短距離輸送(<200km)は、通常1日で完了し、ドライバーは1人であることが多く、休憩時間は最小限です。 しかし、長距離輸送(>200km)は、多くの場合、数日にわたり、必須の重要な休息期間が含まれており、予測やモデル化が困難です。 各輸送タイプに特化したモデルをトレーニングし、それらの予測を統合して出力することにより、両方の輸送タイプの異なる行動を把握し、予測の精度を向上させました。
2. クラス分類モデル
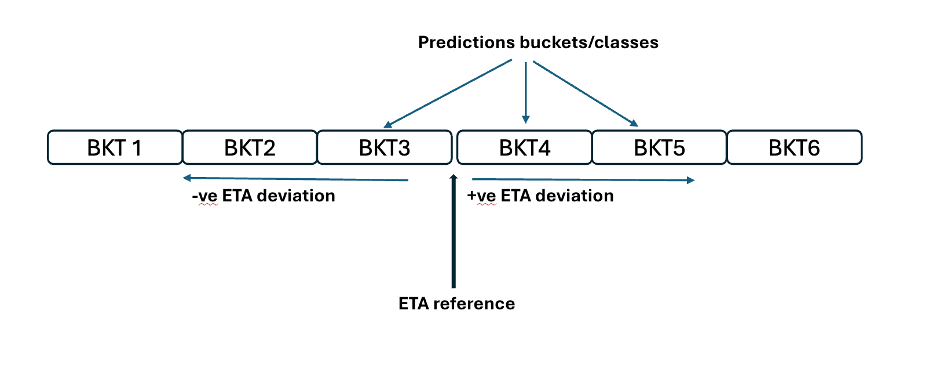
アンサンブルモデルはETAの予測を改善しましたが、一貫性のない滞在行動や車線レベルの違いなど、変動性の高いシナリオでは 単一のポイント推定値を生成するため、依然として苦戦しました。 これに対処するために、分類ベースのアプローチを設計しました。 このモデルは、単一の正確なETAを予測するのではなく、参照時刻(過去のトランジットタイムの中央値や予約時間帯の中間点など)から予測を開始します。 次に、残差(実際のETAと参照の差)を計算し、それらの残差を範囲に分類します。
分類の役割は、最終的なETAがどの時間帯(バケットまたはクラス)に属するかを予測することです。 バケットが特定されると(BKT2など)、ETAは以下のように計算されます。
最終ETA = 参照ETA + 予測バケットの中間点
このバケット化されたアプローチは、モデルが変動をより適切に捉えることを可能にし、導入時の精度を向上させました。
3. トランスフォーマーモデル
ディープラーニングは、ETA予測に明らかな利点をもたらし、特に複雑なパターンを大規模にモデル化する機能を提供します。 1年近くの貨物データで訓練されたトランスフォーマーモデルは、自然に適合しました。 主な強みはAttention Mechanism(注意機構)です。これにより、モデルは交通量の急増、滞在が多発する場所、ルート逸脱など、ETAの精度に不均衡な影響を与える最も適切な要因に焦点を当てることができます。
特徴を個別に扱うツリーベースの方法とは異なり、トランスフォーマーは各信号(ping)とイベントの重要性を文脈内で動的に評価します。 この機能は、精度を大幅に向上させ、数千ものレーンに渡って対応可能な汎化性能を実現しました。 これらの成果により、トランスフォーマーは現在、将来のETA開発におけるベースラインアーキテクチャとなっています。
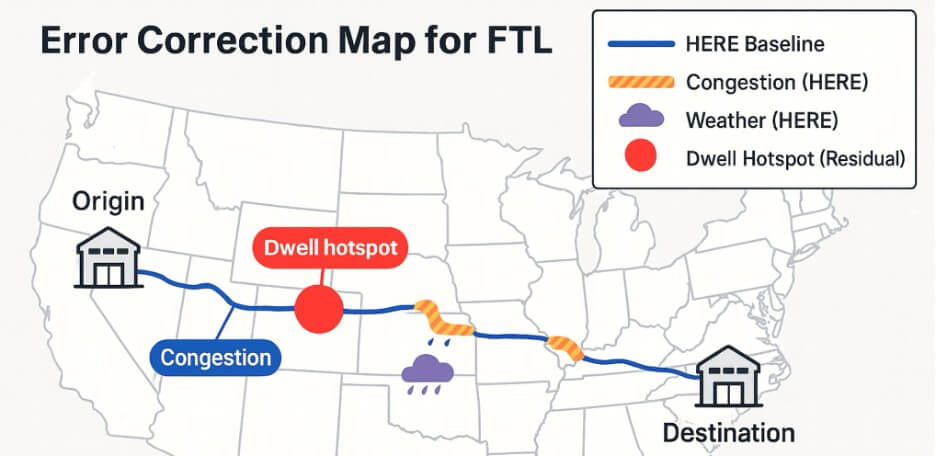
4. 誤差修正モデル(ECM:Error Correction Model)
純粋な走行時間モデルには、停留、中断、施設での遅延などの制約がありますが、残差誤差を学習することでこれらを補正できます。 まず、理想的な条件下での純粋な走行時間を推定するために、疑似決定論的な HERE Maps ベースラインから開始しました。 次に、二次的な機械学習モデルを用いて、停留、キャリアの行動、または中断イベントによって引き起こされる残余遅延を予測しました。 このエラー補正をトランスフォーマーモデルの上に重ねることで、精度がさらに8~10パーセントポイント向上しました。
成果
過去1年間で、500社以上のFTL陸上輸送を追跡する荷主向けに10以上の本番稼働可能なモデルを導入しました。 その結果:10時間先の予測において(±2時間の誤差範囲で)精度が+28パーセンテージポイント向上しました。
荷主にとって、この改善は、より信頼性の高い計画と予期せぬ事象の減少を意味します。また、港湾労働力の再配置、在庫の調整、混乱を回避するための貨物のルート変更など、プロアクティブな意思決定を可能にする十分なリードタイムを提供します。
主要顧客のパフォーマンス
グローバルETAモデルは多くの荷主に有効ですが、中には独自のパターンで業務を行うお客様もいます。その場合、アプローチのカスタマイズが必要になります。 柔軟なモデリングを行うことで実際に良い結果を生んだカスタマイズ例をいくつかご紹介します。
高ボリューム短距離輸送荷主(ヨーロッパ):
このお客様は、毎日非常に多くのフルトラック積載量を扱っていました。 輸送はほとんど同じドライバーが一貫して同じルートを運行しており、そのため変動が低いのが特徴でした。 HERE Mapsベースの残差が非常に狭い分布を示していたため、残差を予測するためにトランスフォーマーモデルを展開しました。 このソリューションにより、精度が20~25パーセントポイント向上するという大きな成果が得られました。
マルチストップ輸送の荷主(北米):
このお客様には、最大14か所にも及ぶ複数の立ち寄り箇所を伴う輸送特徴がありました。 この挙動は、project44の主要モデルがトレーニングされたシナリオとは大きく異なります。 私たちは、いくつかのアプローチを試し、最終的には各停留所での滞留時間を予測するヒューリスティックモデルを開発しました。 HERE Mapsの移動時間とヒューリスティックに基づくスケジュールされた滞留モデルを活用した予測により、精度が35パーセントポイント以上改善されました。
長距離夜間キャリア(北米):
このお客様は、夜間に非常に長距離の輸送を行っており、予定された場所で長時間の底流が発生するケースが多くありました。 弊社は、同様の長距離輸送と複数の停留所のパターンを持つテナントをグループ化し、専用モデルを開発しました。 滞留時間の中央値やレーン特有の滞留特性など、滞留時間に関連する機能を設計しました。 この特殊なモデルは、全体的な精度を8パーセンテージポイント向上させました。
得られた知見
01
データ品質が精度を左右する。
位置情報が高頻度で、正確かつ広範に取得できている場合、到着時間(ETA)はより信頼性が高くなります。 一方、データ品質が低いとパフォーマンスも悪化します。
02
ドリフト(変動)は常に発生する:サプライチェーンは週ごとに変化するため、モデルを最新のパターンに合わせ続けるには、定期的な再トレーニングとドリフトの監視が不可欠です。
03
一つのモデルが全パターンに通用するわけではない:インターモーダル(鉄道輸送 + トラック)、マルチストップ輸送、短距離と長距離のシナリオに専用モデルを導入することで、著しい改善がもたらされました。
04
トランスフォーマーは大きな転換点:トランスフォーマーアーキテクチャに投資し、より大きなモデルを訓練するためのインフラストラクチャの強化により、汎化性能と全体的なパフォーマンスが大幅に向上しました。
05
計画外の事象への対応が非常に重要:予定外または長時間・週末の滞留、アポイントメントのキャンセル・変更は誤差を発生させる主な要因であり、慎重な機能エンジニアリングが求められます。
06
エラー補正が精度を押し上げる:エラー訂正アプローチなどの代替モデリング技術(HERE/planの基準値を上回る残差など)により、ETAの精度が大幅に向上しました。
07
強力な基盤がすべてを増幅する:プロアクティブな監視、再トレーニングの体系化、より大規模な履歴データコーパスなどが相乗効果を発揮し、すべてモデルの改善を加速させています。
今後の展望
精度が+28パーセンテージポイント向上したとしても、弊社はここで立ち止まりません。 ETA(到着予定時刻)のパフォーマンスをさらに向上させるためのいくつかの取り組みがすでに進行中です。
- テナント対応型ポストプロセッシング: 単一のグローバルモデルをテナント(顧客)グループに適応させる軽量レイヤーを追加します。 これにより、個別モデルを作成することなく、類似した荷主グループごとに出力を微調整できます。
- テナントプロファイラー: 新しいモジュールとして、運用パターン(輸送レーン、サービスレベル、ドウェル挙動など)を共有するテナントをクラスタリングし、上記のポストプロセッシング層を支援します。
- 大規模な分散型トレーニング: 分散トレーニングフレームワークに投資し、複数ノード間で学習を並列化することで、より大きな履歴データコーパスでの学習を可能にし、収束の高速化と汎化性能の向上を実現します。
- より深い説明性の追求: 分散トレーニングフレームワークに投資し、複数ノード間で学習を並列化することで、より大きな履歴データコーパスでの学習を可能にし、収束の高速化と汎化性能の向上を実現します。
これらの取り組みは、強固な機械学習運用体制(MLOps)と文脈に基づく説明を核としたモデル群を補完し、ETA精度をさらに高めます。